K نزدیک ترین همسایه (K-nearest neighbour)
KNN نوعی الگوریتم دسته بندی یادگیری مبتنی بر نمونه است. اصل روش KNN این است که در فضای ویژگی، یک نمونه دارای K نزدیک ترین نمونه است و برچسبش به رایج ترین کلاس در میان KNN هایش با استفاده از رأی اکثریت همسایه هایش تخصیص می یابد. بدون دانش قبلی، الگوریتم دسته بندی KNN به طور متناوب از فاصله اقلیدسی به عنوان معیار فاصله استفاده می کند. با در نظر گرفتن دو بردار x = ( x1 , x2 , ... ,xm ) و y = ( y1 , y2 , ... , ym ) ، فاصله اقلیدسی آن ها به صورت زیر نمایش داده می شود:
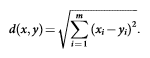
گروه تحقیقاتی سیبی از ویژگی های هندسی برای دستیابی به بهترین صحت دسته بندی 93% روی پایگاه داده ی Cohn-Kanade با روش KNN استفاده کرده است. گروه تحقیقاتی گو، روش FER را با استفاده از رمز گذاری شعاعی ویژگی های محلی گابور و سنتز دسته بندی کننده ی مبتنی بر روش KNN با K=1 اراِئه کرده است.