ماشین بردار پشتیبان(Support vector machine)
SVM ها (Support vector machine) بر مبنای اصل کمینه سازی ریسک ساختاری توسعه می یابند که نشان داده شده است که برتر از اصل کمینه سازی ریسک تجربی سابق استفاده شده توسط شبکه های عصبی قراردادی می باشند. اصل SVM، تبدیل بردارهای ورودی به فضایی با ابعاد بیشتر توسط تبدیل غیر خطی و سپس ابر صفحه ی بهینه است که داده هایی را که قابل یافتن هستند را تفکیک می کند. با در نظر گرفتن مجموعه آموزشی 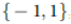
 ، برای جست و جوی ابر صفحه ی بهینه، تبدیل غیر خطی
، برای جست و جوی ابر صفحه ی بهینه، تبدیل غیر خطی 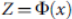 برای قابل تقسیم ساختن خطی داده های آموزشی استفاده می شود. وزن w و مبدأ b طبق ضوابط زیر در نظر گرفته می شوند:
برای قابل تقسیم ساختن خطی داده های آموزشی استفاده می شود. وزن w و مبدأ b طبق ضوابط زیر در نظر گرفته می شوند:

روند بالا با استفاده از مسئله بهینه سازی زیر خاتمه می یابد:
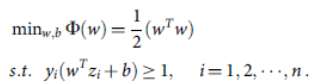
با استفاده از روش لاگرانژ، تابع تصمیم می تواند به صورت زیر نوشته شود:

طبق ایده ی هسته ای، تابع تقارن غیر منفی K(u ,v) به طور منحصر به فرد، فضای هیلبرت H را نشان می دهد:

که در آن K، تابع هسته در فضای H است که نشان دهنده ضرب داخلی در فضای هیلبرت H است:

بنابراین، تابع تصمیم می تواند به صورت زیر بازنویسی شود:

چهار تابع هسته نوعی برای مدل SVM استفاده شده وجود دارد که شامل هسته خطی، هسته چند جمله ای، هسته RBF و هسته حلقوی است که به صورت زیر بیان می شود:
تابع هسته خطی برابر است با:

تابع هسته ی چند جمله ای برابر است با:

تابع هسته ی RBF برابر است با:
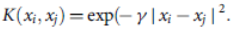
تابع هسته ی حلقوی برابر است با:

یورتکان و دمیرل از طبقه بندی کننده ی SVM برای توسعه ی سیستم انتخاب ویژگی برای FER بهبود یافته با استفاده از موقعیت های نقطه ی ویژگی چهره ی هندسی سه بعدی استفاده کردند. گیمیر و لی روش FER مبتنی بر ویژگی هندسی را در دنباله های تصویر چهره ارائه کردند و صحت %97.35 را با استفاده از دسته بندی کننده SVM روی پایگاه داده ی Cohn-Kanade گزارش کردند.
K نزدیک ترین همسایه (K-nearest neighbour)
KNN نوعی الگوریتم دسته بندی یادگیری مبتنی بر نمونه است. اصل روش KNN این است که در فضای ویژگی، یک نمونه دارای K نزدیک ترین نمونه است و برچسبش به رایج ترین کلاس در میان KNN هایش با استفاده از رأی اکثریت همسایه هایش تخصیص می یابد. بدون دانش قبلی، الگوریتم دسته بندی KNN به طور متناوب از فاصله اقلیدسی به عنوان معیار فاصله استفاده می کند. با در نظر گرفتن دو بردار x = ( x1 , x2 , ... ,xm ) و y = ( y1 , y2 , ... , ym ) ، فاصله اقلیدسی آن ها به صورت زیر نمایش داده می شود:
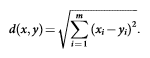
گروه تحقیقاتی سیبی از ویژگی های هندسی برای دستیابی به بهترین صحت دسته بندی 93% روی پایگاه داده ی Cohn-Kanade با روش KNN استفاده کرده است. گروه تحقیقاتی گو، روش FER را با استفاده از رمز گذاری شعاعی ویژگی های محلی گابور و سنتز دسته بندی کننده ی مبتنی بر روش KNN با K=1 اراِئه کرده است.
دسته بندی حالت چهره (Facial expression classification)
هدف دسته بندی حالت چهره ، طراحی یک مکانیزم دسته بندی مناسب برای شناسایی حالت چهره است. روش های دسته بندی نمونه برای FER شامل مدل مارکوف نهفته (Hidden Markov Model)، شبکه عصبی مصنوعی (Artificial Neural Network)، شبکه بیز (Bayesian Network)، نk نزدیک ترین همسایه (K-nearest neighbour)، ماشین های بردار پشتیبان (Support Vector Machines)، دسته بندی مبتنی بر نمایش پراکنده(Sparse Representation-based Classification)، و مواردی از این قبیل می باشند.
مدل های تبدیل ویژگی مقباس نامتغییر (Scale-invariant feature transform)
تبدیل ویژگی های مقیاس نا متغییر یا Scale-invariant feature transform (SIFT) یک توصیفگر محلی تصاویر برای تطبیق مبتنی بر تصویر است که برای اولین بار در کانادا در دانشگاه بریتیش کلمبیا توسط دیوید لاو در سال 1999 پیشنهاد شده است. برنامه های کاربردی SIFT شامل تشخیص شی ، نقشه برداری رباتیک و ناوبری، دوخت تصویر، مدل سازی 3D ، تشخیص حرکت، ردیابی ویدئو، شناسایی فرد از حیات وحش و بازی در حال حرکت می باشد. شکل زیر نشان دهنده یک مثال از روش استخراج ویژگیSIFT است که توسط برتی و سایر همکارانش استفاده شده اند که آن ها ازنشان های اختصاصی چهره در مناطق ریخت شناسی مهم صورت به عنوان نقاط کلیدی استفاده نموده اند و پس از آن ،از استخراج کننده ویژگیSIFT در این نقاط کلیدی برای به دست آوردن توصیف کننده SIFT استفاده نموده اند. اخیرا"، دمریل و سایر همکارانش یک روش تشخیص دهنده تبدیل ویژگی های مقیاس نامتغییر (D-SIFT) را پیشنهاد نموده اند که می تواند به صورت کارایی تصمیمات زیادی را بر روی ویژگی های ظاهری کلی اتخاذ نماید. لی و سایر همکارانش یک روش جدید تبدیل ویژگی های مقیاس نامتغییر را تحت عنوانGA-SIFT برای تصاویر چند طیفی با استفاده از جبر هندسی (GA) پیشنهاد کرده اند. در ابتدا، بر اساس تئوری، یک روش جدید نمایش برای تصاویر چند طیفی با اطلاعات فضایی و طیفی معرفی شده است. سپس، فضای مقیاس برای تصاویر چند طیفی محاسبه شده است.بعد از این مرحله، مشابه SIFT اختلاف مبتنی بر GA تصاویر گاوسی به دست آمده است. در نهایت، نقاط ویژگی را شناسایی نموده و با استفاده از تئوری GA شرح می دهیم. در شکل زیر روش استخراج ویژگی SIFT استفاده شده است. الف) تصویر نمونه و خطوطی که در طول آن 85 نشانه اضافی قرار گرفتند. ب) تعداد نشانه ها برای هر مولفه چهره ای که به آن تعلق دارند.

(ب) (الف)
مدل ظاهر فعال (Active appearance model)
مدل ظاهر فعال یا Active appearance model توسط کوتس و سایر همکارانش در سال 2001 معرفی شده است . این روش، راهکار ASM را با نگه داشتن اطلاعات شکل و بافت به صورت هم زمان، توسعه می دهد. در جزییات این روش باید بیان نمود که ASM در ابتدا به صورت یک مدل آماری مبتنی بر داده های آموزشی برای آنالیز آماری طراحی شد. سپس از این مدل آماری برای پیاده سازی محاسبات مناسب برای تست داده ها استفاده شد. بر خلاف AAM ،ASM که تنها از مزیت اطلاعات بافت و شکل سراسری استفاده می کنند، می توان از آنالیز آماری بر روی اطلاعات بافت محلی برای یافتن روابط بین اطلاعات یافت و شکل استفاده نمود. چوئن و سایر همکارانش یک روش FER را با استفاده از AAM تشخیص دهنده و یادگیری چند شاخه ای پیشنهاد نمودند. اختلاف پارامترهای AAM بین تصاویر ورودی و تصاویر مرجع به منظور استخراج ویژگی های تشخیص دهنده AAM محاسبه می شوند. سپس روش های یادگیری چند ویژگی های تشخیص دهنده AAM محاسبه می شوند. سپس روش های یادگیری چند شاخه ای برای تعبیه کردن DAF ها در فضای ویژگی های متوالی و هموار، مورد استفاده قرار می گیرند. در نهایت حالت چهره ورودی شناسایی می شود. در سال های اخیر، نسخه های بسیار زیادی از AAM ها توسعه یافته اند که شامل روش های AAM مبتنی بر هیستوگرام مبتنی برگرادیان AAM، (HOG) مبتنی بر تراکم و AAM مبتنی بر رگرسیون است. بررسی کارایی این روش های جدید توسعه یافته از اهمیت بالایی برخوردار خواهد بود.