مدل شکل فعال (Active shape model)
مدل شکل فعال یا به عبارتی Active shape model (ASM) توسط کوتس و همکارانش به عنوان یک روش تطبیق ویژگی مبتنی بر مدل آماری است، به این دلیل که اشکال بوسیله ی یک مجموعه نقاط توصیف می شود. ASM ترکیبی از مدل توزیع نقطه ای (PDM) برای یادگیری تغییرات شکل های قابل قبول و تعدادی از مدل های انعطاف پذیر برای نگه داشتن سطوح خاکستری اطراف نقاط ویژگی اختصاصی است. شکل زیر یک مثال را با استفاده از روش استخراج ویژگی نقاط ویژگی نقطه عطفی را نشان می دهد که در آن از 58 نقطه ویژگی اختصاصی چهره استفاده شده است. روش نقاط ویژگی نقطه عطفی از دو مرحله تشکیل شده است. اولین مرحله، مدل اشکال است که از نمونه های آموزشی به همراه برخی از نقاط ویژگی اختصاصی تفسیر شده، بدست آمده اند. سپس، مدل های بافت محلی برای هر یک از نقاط ویژگی اختصاصی نیز ساخته می شود. در مرحله ی دوم، مطابق با مدل های ساخت، از یک فرآیند جست و جوی تکراری برای تغییر شکل مدل استفاده می شود. مهمترین برتری استفاده از ASM این است که هیچ فرض جدیدی در مورد شکل های واقعی صورت نمی گیرد. در واقع شکل ها را مطابق مجموعه دیده شده بدون هیچ فرضیات شکلی معتبری توصیف می کند. زوهو و سایر همکارانش از جا به جایی هندسی بین مختصات نقاط ویژگی ASM طراحی شده و میانگین شکل ASM به عنوان ویژگی چهره برای FER استفاده نمودند. در سال های اخیر، اندرسون و سایر همکارانش یک نسخه ی توسعه یافته تری از ASM را ارائه نمودند که نام آن مدل آماری و شکل فعال (ASSM) برای تشخیص چهره است و دارای توان بسیار زیادی در کاربردهای FER است.

استخراج ویژگی چهره
یک سیستم تشخیص چهره معمولا" شامل 3 بخش می باشد:
1.آشکار سازی چهره
2.استخراج حالات چهره
3.تشخیص چهره
تشخیص چهره یک حالت مهم از استخراج و تفسیر حالت های احساسی و حالت های روانی برای انسان ها است. در روانشناسی، مهرابیان و سایر همکارانش به این نتیجه رسیده اند که تنها 7 درصد از اطلاعات وابسته به انسان ها در بین زبان ها قابل حمل هستند، 38 درصد از حمل این اطلاعات از طریق گفتار انجام می شود و 55 درصد از آن ها توسط حالات چهره قابل حمل هستند. از این رو تشخیص حالات چهره می تواند اطلاعات بسیار ارزشمندی را برای ما فراهم نموده و می توان از آن برای شناسایی آگاهی و فعالیت های ذهنیشان استفاده نمود. هدف اصلی روش های تشخیص حالات چهره، توسعه ی سیستم های دقیق، کارا و خودکار برای تمایز قائل شدن بین حالت های مختلف چهره و در نتیجه تعیین احساسات انسان ها با استفاده از حالت های چهره است که می تواند شامل مواردی از قبیل خوشحالی، ناراحتی، عصبانیت، ترس، هیجان و نفرت باشد. FER های خودکار به صورت چشمگیری توسعه یافته اند و توجهات زیادی را در زمینه های بینایی ماشین، تشخیص الگو و هوش مصنوعی به علت کاربردهای بالقوه آن در تعاملات انسان و کامپیوتر، آنالیز احساسات انسان، ویدیوهای تعاملی، شاخص گذاری تصاویر و بازیابی تصاویر به خود جلب نموده اند. در اصل، یک سیستم FER پایه از دو مرحله ی اصلی تشکیل شده اند: استخراج ویژگی های چهره و دسته بندی حالت های چهره.
استخراج حالات چهره یک راهکار برای استخراج ویژگی های چهره از تصویر چهره ورودی برای نشان دادن کارایی حالت های چهره است. بر اساس انواع مختلفی از تصاویر ورودی، روش های استخراج ویژگی های چهره را می توان به 2 دسته ی مختلف تقسیم نمود:
1.روش های استخراج ویژگی های چهره برای تصاویر ایستا بدون گوناگونی است.
2.روش های استخراج ویژگی برای دنباله ای از تصاویر پویا است.
برای تصاویر ایستا، دو نوع از روش های استخراج ویژگی وجود دارند: روش های مبتنی بر ویژگی های هندسی و روش های مبتنی بر ظاهر.
- روش های مبتنی بر ویژگی های هندسی: چهره ی انسان از ابرو ها، چشم ها، مژه ها، دماغ، دهان، چانه و موارد دیگری تشکیل شده اند. اندازه، مسیر، موقعییت و بسیاری از موارد دیگر تأثیر زیادی در استخراج حالت های چهره دارد. از این رو ویژگی های هندسی رامی توان برای نشان دادن موقعیت و شکل مؤلفه های چهره مانند: دماغ، دهان و یا ابروها استفاده نمود. هدف اصلی روش های مبتنی بر ویژگی های هندسی استفاده از روابط هندسی بین نقاط ویژگی چهره برای استخراج ویژگی های چهره است. با این حال، استخراج ویژگی های چهره معمولا" نیازمند تکنیک های شناسایی نقاط ویژگی با دقت بسیار بالایی است. روش های مبتنی بر ویژگی های هندسی می توانند خیلی راحت تغییرات در بافت تصویر را که شامل مواردی از قبیل چین و چروک هستند را نادیده بگیرند که به عنوان عوامل بسیار مهم و تأثیر گذاری در مدل بندی حالت های چهره هستند. یک نوع اصلی از روش های استخراج ویژگی های چهره وجود دارند که شامل موارد زیر هستند: مدل های شکل فعال(ASM)، مدل های ظاهر فعال(AAM)، مدل های تبدیل ویژگی مقیاس نامتغییر(SIFT).
- روش های مبتنی بر ظاهر: هدف اصلی روش های مبتنی بر ظاهر استفاده از تمام چهره و یا مناطق خاصی از تصویر چهره برای بازتاب اطلاعات مخفی شده در تصویر چهره است. این روش برای نشان دادن تغییرات چهره مانند چین و چروک ها بسیار مناسب هستند. در حالت کلی دو روش اصلی برای روش های استخراج ویژگی های چهره مبتنی بر ظاهر وجود دارد: الگوهای باینری محلی(LBP)، نمایش طول موج گابور.
روش های استخراج حالت چهره برای دنباله ای از تصاویر پویا :
دنباله ای از تصاویر پویا نشان دهنده ی فرآیند ادامه داری است که برای استخراج ویژگی های چهره ار آن استفاده می شود. ویژگی های حالات چهره برای دنباله ای از تصاویر پویا در حالت کلی با استفاده از حرکات چهره و تغییر شکل چهره نشان داده می شوند. دو روش مشهور برای استخراج حالات چهره برای دنباله ای از تصاویر پویا وجود دارد: جریان نوری و ردیابی نقاط ویژگی.
تبدیل الگوی باینری محلی ( Local binary pattern)
الگوریتم الگوی باینری محلی (LBP) در سال 1994 ابداع گردید. الگوریتم LBP یکی از قویترین الگوریتم های استخراج ویژگی در علم بینایی ماشین است و همچنین یکی از روش هایی است که به طور وسیعی در تحقیقات مربوط به چهره و بازیابی چهره به کار رفته است. الگوهای باینری محلی روشی موثر برای توضیح کارای بافت ها است که می توان از آن برای اندازگیری استخراج ویژگی های بافت های مجاور در تصاویر استفاده نمود. مزیت استفاده از این روش این است که اپراتور الگوهای باینری محلی دارای تغییر ناپذیری چرخش و تغییر ناپذبری سطح خاکستری بالایی بوده و می توان با استفاده از این روش بر مشکلات عدم تعادل در تغییر موقعیت، چرخش و نور افکنی، غلبه نمود. علاوه بر این اپراتور LBP دارای محاسبات بسیار ساده ای است. شکل زیر نشان دهنده یک مثال از استخراج ویزگی ها توسط LBP برای FER است.در این مثال این روش استفاده شده شامل 3 مرحله اصلی است. یک تصویر چهره به دو بلوک مختلف غیر هم پوشانی شده تقسیم شده است. بعد از تقسیم برای هر بخش هیستوگرام FER به کار گرفته شده است. در نهایت هیستوگرام های بلوک های FER داخل یک بردار تکی نشان داده شده توسط کد LBP ادغام شده اند. در مقالات قبلی، ما کارایی اپراتور LBP را با روش های کاهش ابعاد مختلفی در وظایف FER مورد بررسی و مقایسه قرار داده ایم. در سالهای اخیر، انواع مختلفی از اپراتورهای FER را می توان در مقالات یافت. اما امروزه انواع مختلفی از LBP های معمول شامل الگوهای باینری محلی حجیم LBP ،(VLBP) بر روی طرح های سه گوشه (LBP-TOP)، الگو های وابسته محلی (LBP-TOP)، الگوهای سنتی محلی (LTP) و بسیاری از موارد دیگر است. در سال های اخیر، لی و سایر همکارانش الگو های باینری محلی بلوک های چند گانه چند نوعی (P-MLBP) را برای FER سه بعدی تمام خودکار پیشنهاد نمودند. P-MLBP از تقسیم نا منظم مبتنی بر ویژگی برای نشان دادن دقیق حالات چهره و همچنین ادغام عمق و بافت اطلاعات مدل های سه بعدی برای بهبود ویژگی های چهره استفاده نمودند.

شکل1
الگوی دودویی محلی (LBP) اپراتور بافت ساده و بسیار کار آمد است که عددهای هر تصویر را با آستانه محاسبه هر پیکسل نشان می دهد و نتیجه را به عنوان عدد دودویی در نظر می گیرد. با توجه به قدرت تبعیض آمیز و سادگی محاسباتی، اپراتور بافت LBP در برنامه های کاربردی مختلف به یک رویکرد رایج تبدیل شده است. این را می توان به عنوان یک رویکرد متحد به مدل های آماری و ساختاری سنتی تجزیه و تحلیل بافت مشاهده شده است. شاید مهمترین ویژگی اپراتورLBP در برنامه های کاربردی در دنیای واقعی ، توانی آن در تغییرات خاکستری تک رنگ است که باعث ایجاد تغییرات نور می شود. یکی دیگر از ویژگی های مهم، سادگی محاسباتی آن است که امکان تجزیه و تحلیل تصاویر را در تنظیمات زمان واقعی به چالش کشیدن امکان می دهد.

شکل 2: توصیف عبارات صورت با الگوهای باینری محلی
ایده اصلی برای توسعه اپراتور LBP این است که بافت سطحی را می توان با دو روش مکمل توصیف کرد: الگوهای فضایی محلی و مقایسه کردن مقیاس خاکستری. اپراتور اصلی LBP (OJALA و همکارانش در سال1996 ) بر چسب ها را برای پیکسل های تصویر با آستانه محدوده 3*3 هر پیکسل با ارزش مرکزی و با توجه به نتیجه به عنوان یک عدد دودویی می سازد. هیستوگرام این 256=2^8 بر چسب های مختلف می تواند به عنوان یک توصیفگر بافت استفاده می شود. این اپراتور با استفاده از روش مقایسه کردن ساده محلی استفاده شده و عملکرد بسیار خوبی را در تقسیم بندی بافت بدون نظارت ارائه داد (Ojala & Pietikainen 1999). پس از این بسیاری از روش های مرتبط برای تقسیم بافت و بافت رنگ طراحی شده است. اپراتور LBP برای استفاده از همسایگی های مختلف انداز گیری شد (Ojala و همکارانش 2002) با استفاده از همسایگی دایره ای و مقادیر دو قطبی بین مقادیری در مختصات پیکسل غیر عدد صحیح به هر شعاع و تعداد پیکسل ها در همسایگی اجازه می دهد. واریانس مقیاس خاکستریهمسایگی محلی می تواند به عنوان اندازه گیری مقایسه کردن مکمل استفاده شود. در زیر، علامت (P,R) برای همسایگی های پیکسل مورد استفاده قرار می گیرد که به معنی نقطه های نمونه گیری P در یک دایره شعاع R است. برای مثال، برای محاسبه LBP به شکل 3 مراجعه کنید.

شکل 3: نمونه ای از محاسبات LBP
توسعه دیگری برای اپراتور اصلی ، که به اصطلاح تعریف الگوهای یکنواخت هست، که می تواند برای کاهش طول بردار ویژگی و از یک توصیفگر چرخش غیر مجاز استفاده شود. این افزونه از این واقعیت الهام گرفته شده است که برخی از الگو های باینری بیشتردرتصاویر بافت از دیگران به نمایش در می آیند. یک الگوی دودویی حاوی بیش از دو انتقال بیتی به صورت دایره ای متقاطع می شود. به عنوان مثال، الگوهای 00000000(0 انتقال)، 01110000 (2 انتقال) و 11001111(2 انتقال) یکنواخت هستند، در حالی که الگوهای 11001001(4 انتقال) و 01010010(6 انتقال) نیستند. در محاسبه بر چسب های LBP الگوهای یکنواخت استفاده می شود به طوری که یک بر حسب جداگانه برای هر یک از الگوی یکنواخت وجود دارد و تمام الگوهای غیر یکنواخت با یک بر چسب واحد بر چسب گذاری می شوند. به عنوان مثال، هنگام استفاده از (R,8) همسایگی Ojala و همکارانش (2002) در آزمایش های خود با تصاویر بافتی متوجه شدند که الگوهای یکنواخت در هنگام استفاده از همسایگی (8,1) و حدود70 درصد درهمسایگی (16،2)، کمی کمتر از 90 در صد از همه الگوها را تشکیل می دهند. هر کد بندی (کدLBP) را می توان به عنوان یک میکروفون در نظر گرفت. ابتدای محلی که توسط این ها کد گذاری می شوند شامل انواع مختلف لبه های منحنی، نقاط، مناطق مسطح و غیره می باشد. نماد زیر برای اپراتورLBP استفاده می شود : P, R^U2
LBP این شاخص نشان دهنده استفاده از اپراتور در همسایگی (P،R) است Superscript U2 برای استفاده از تنها الگوهای یکنواخت و بر چسب گذاری همه الگوهای باقیمانده با یک بر چسب واحد است. پس از تصویر LBP دارای بر چسب FL تصویر (X,Y) به دست آمده است. هیستوگرام LBP را می توان به صورت زیر تعریف کرد:
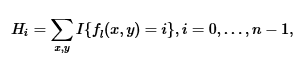
که در آن n تعداد برچسب های مختلف تولید شده توسط اپراتورLBP است و I { A } است . 1 اگر A درست باشد و 0 اگر A اشتباه باشد. هنگامی که تصویر تکه هایی که هیستوگرام های مورد نظر باید مقادیر مختلفی داشته باشند، اندازه های مختلفی دارند، هیستوگرام ها باید برای توصیف یکپارچه سازی نرمال شوند:
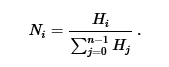
توضیحات صورت با استفاده از LBP
در روش LBP برای طبقه بندی بافت، وقایع کد LBP در تصویر به یک هیستوگرام جمع آوری می شوند. سپس طبقه بندی با محاسبه ی شباهت های هیستوگرام ساده انجام می شود. با این حال، با توجه به یک روش مشابه برای نمایش تصویر چهره، در نتیجه از دست دادن اطلاعات بافت را در حالی که مکان های خود را حفظ می کنند تدوین کنند. یک راه برای رسیدن به این هدف این است که از توصیفگرهای بافت LBP برای ساختن چندین توصیف محلی از چهره استفاده کنید و آن ها را به یک توصیف جهانی تر کیب کنید. چنین تو صیف های محلی به تازگی به دست آورده است که با توجه به محدودیت های نمایندگی های کلی قابل فهم است. این روش مبتنی بر ویژگی های محلی در برابر تغییرات در ظاهر یا نور نسبت به روش های جامع قوی تر است. روش اساسی برای توصیف چهره LBP پیشنهاد شده توسط Ahonen و همکارانش در سال( 2006) به شرح زیر است :
تصویر چهره به مناطق محلی تقسیم می شود و توصیفگر های بافت LBP به طور مستقل از هر منطقه استخراج می شوند. سپس توصیفگر ها برای تشکیل یک توصیف جهانی چهره، به شکل 4 نشان داده شده اند.

شکل 4: توصیف چهره با الگوهای باینری محلی
این هیستوگرام به طور موثر چهره را در سه سطح مختلف نشان می دهد:
برچسب های LBP برای هیستوگرام حاوی اطلاعات در مورد الگوهای در سطح پیکسل هستند، برچسب ها در یک منطقه ی کوچک به منظور جمع آوری اطلاعات در سطح منطقه و هیستوگرام های منطقه برای ساختن یک توصیف جهانی از چهره به یکدیگر متصل می شوند. لازم به ذکر است که هنگام استفاده از روش های مبتنی بر هیستوگرام، مناطق نیازی به مستطیلی نیستند. آن ها نیازی به اندازه و شکل ندارند و لزوما باید تمام تصویر را پوشش دهند. همچنین ممکن است بخشی از مناطق همپوشانی داشته باشد. روش توصیف چهره دو بعدی به دامنه ی فضایی و زمانی گسترش یافته است(Zahao & Pietikainen 2007) . شکل 1 توضیح بیان صورت با استفاده از LBP-TOP را نشان می دهد. عملکرد مناسب تشخیص بیان چهره با این روش بدست آمده است. از زمان انتشار توضیح چهره مبتنی بر، LBP روش شناسی در حال حاضر موقعیتی ثابت در تحقیقات و برنامه های کاربردی تجزیه و تحلیل صورت داشته است. یک مثال قابل توجه این است که سیستم تشخیص چهره غیر قابل تصوری پیشنهاد شده توسط Li و همکارانش در سال 2007، ترکیب تصویر برداری NIR با ویژگی های LBP و یادگیری. Adaboost ژانگ و همکارانش در سال 2005، استخراج ویژگی های LBP از تصاویر گرفته شده توسط فیلتر کردن یک تصویر صورت با 40 فیلتر گابور از مقیاس ها و جهت های مختلف ، نتایج برجسته ارائه شده است. Hadid و Spatiotemporal برای تشخیص چهره و جنس از توالی های ویدئویی استفاده کردند، در حالی که ژائو و همکارانش در سال 2009 رویکرد گفتار بصری به دست آوردند عملکرد پیشرو بدون تقارن خطا لب های متحرک به تصویب رسید.
پیشرفت های اخیر
موفقیت LBP از سال 2011 ادامه داشته است. تعداد زیادی از انواع جدید LBP پیشنهاد شده است، برای مثال اپراتور Median Robust Extended Local Binary Pattern(MRELBP) لوئی و همکارانش در سال2016. یک ارزیابی تجربی گسترده از توصیفگرهای LBP مختلف و بافت های عمیق توسط لوئی و همکارانش در سال 2016 ارائه شده است. استحکام اپراتور های بافت در برابر چالش های طبقه بندی متفاوت شامل تغییر در چرخش، مقیاس، روشنایی، دیدگاه، تعداد کلاس ها، انواع مختلف تخریب تصویر و محاسبات پیچیدگی می باشد. بهترین عملکرد کلی برای MRELBP زمانی به دست می آید که تمایز، قابلیت اطمینان و پیچیدگی محاسباتی مورد توجه قرار گیرد. پس از این مطالعه، طبقه بندی انواع LBP همراه با ارزیابی تجربی گسترده (لوئی و همکارانش 2017) ارائه شده است.
تبدیل گابور
نمایش طول موج گابور یک روش کلاسیک برای استخراج ویژگی های حالات چهره است. در جزییات، یک تصویر توسط یک مجموعه از فیلترها، فیلتربندی می شود، نتایج فیلتر شده می توانند بازتاب دهنده ی روابط بین پیکسل های محلی باشند. روش نمایش طول موج گابور به صورت گسترده ای برای استخراج ویژگی های حالت های چهره استفاده می شود. این روش می تواند مقیاس های چندگانه، تغییرات چند جهته برای بافت ها را شناسایی نموده و تأثیر نور افکنی در آن بسیار کم است. شکل زیر نشان دهنده ی یک مثال از این روش است که در آن 18 گوشه گابور در مقیاس 3 و در 6 جهت به کار برده شده اند. لئو و سایر همکارانش یک روش FER مبتنی بر ویژگی های طول موج گابور و آنالیز مؤلفه های اصلی مرکزی (KPCA) پیشنهاد نموده اند. در این طرح، آن ها از فیلترهای گابور محلی برای جایگذاری با فیلتر گابور سنتی استفاده نموده اند که نتیجه آن افزایش سرعت محاسبات بوده است. گو و سایر همکارانش از رمز گذاری شعاعی ویژگی های گابور محلی و ترکیب دسته بند، FER را انجام داده اند. در این مقاله(A Review on Facial Expression Recognition: Feature Extraction and Classification) تصاویر ورودی ابتدا در معرض عملیات فیلتر گابور چند مقیاسه محلی قرار گرفته اند. سپس تجزیه گابور سر تا سری برای رمز گشایی استفاده شده است. در سال های اخیر، اوسو و سایر همکارانش یک سیستم FER مبتنی بر AdaBoost عصبی را پیشنهاد نمودند که در آن تکنیک های استخراج ویژگی گابور برای استخراج بخش بزرگی از ویژگی های چهره با نمایش الگوهای تغییر شکل چهره، استفاده شده اند.

مثال: در شبیه سازی زیر به بررسی و رسم دو تابع گابور در متلب پرداخته شده است. نتیجه اجرای برنامه مطابق شکل فوق می باشد:

کد متلب آن نیز به صورت زیر می باشد:
% Compute two Gabor functions often also
% called Gabor atoms, or also gaborettes.
t=-10:0.001:10;
b1=0;
a1=1;
b2=6;
a2=1./1.9;
g1=real(exp((-((t-b1)).^2)).*(exp(i.*((2).*pi).*((t-b1)))));
g2=real(exp((-((t-b2)).^2)).*(exp(i.*((4).*pi).*((t-b2)))));
plot(t,g1,'b',t,g2,'b');
axis([-10 10 -2.05 2.05]);
title('Two Gabor functions');
روش viola-jones در تشخیص چهره
یکی از مهم ترین فعالیت های انجام شده در تشخیص چهره روش viola-jones در سال های 2001 و 2004 می باشد. که این روش بسیار موفق و سریع بشمار می آید.
viola و jones الگوریتم AdaBoost را با Cascade برای تشخیص چهره ترکیب کردند. الگوریتم پیشنهادی آنها می توانست چهره را داخل یک تصویر 288*384 با صرف زمانی معادل 0.067 ثانیه تشخیص بدهد. یعنی 15 بار سریع تر از آشکار سازی های state-of-the-art با دقتی بالاتر ،به طوری که این الگوریتم یکی از پیشرفته ترین الگوریتم های ماشین بینایی در دهه ی گذشته تا به حال بوده است. نقش AdaBoost در این الگوریتم به این صورت می باشد که در ابتدا تصویر مورد نظر به زیر تصاویر(24*24) تقسیم بندی می شود. هر دیر تصویر بیانگر یک بردار ویژگی می باشد. به دلیل اینکه محاسبات موثر و کارآمد باشد از یک سری ویژگی های خیلی ساده استفاده می کنیم. تمام مستطیل های ممکن داخل زیر تصویر بررسی می شوند، در هر مستطیل 4 نمونه ویژگی به کمک ماسک هایی که در شکل زیر آمده استخراج می شود. (4 ماسک ویژگی که برای هر مستطیل استفاده می شود.)

با هر یک از این ماسک ها، مجموع پیکسل های سطح خاکستری در نواحی سفید از مجموع پیکسل های نواحی سیاه، کم می شود، که این مقدار به عنوان یک ویژگی دز نظر گرفته می شود. پس می توانیم به این صورت بگوییم که داخل یک زیر تصویر (24*24) بالغ بر یک میلیون ویژگی می توانیم داشته باشیم ( البته این ویژگی ها خیلی سریع محاسبه می شوند و می توانند کمتر از یک میلیون ویژگی هم باشند مثلا" 160000 در هر زیر تصویر)
هر ویژگی به عنوان یک یادگیرنده ی ضعیف در نظر گرفته می شود یعنی :
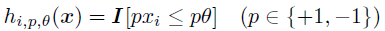
الگوریتم یادگیری پایه تلاش می کند که بهترین کلاسیفایر ضعیف 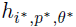 را که، کوچک ترین خطا را در کلاس بندی دارد پیدا کند.
را که، کوچک ترین خطا را در کلاس بندی دارد پیدا کند.
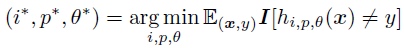
مستطیل های چهره را به عنوان مثال های Positive در نظر می گیریم. ( مثال های آموزشی مثبت )

و مستطیل هایی که شامل تمام چهره نمی شوند، به عنوان مثال های آموزشی Negative تلقی می شوند. سپس الگوریتم AdaBoost را اعمال می کنیم، ایشان تعدادی یادگیرنده ی ضعیف را بر می گردانند، که هر کدام از اینها مربوط به یکی از یک میلیون ویژگی هایی هست که داریم. در واقع اینجا، AdaBoost می تواند به عنوان یک ابزار برای انتخاب ویژگی در نظر گرفته شود.
در ابتدا دو ویژگی و موقعیت مربوط به آنها در چهره انتخاب می شود. که هر دو ویژگی بصری هستند، که اولین ویژگی اختلاف مقدار شدت روشنایی نواحی چشم و قسمت های پایین تر از آن را اندازه گیری می کند و دومین ویژگی اختلاف مقدار شدت روشنایی نواحی چشم ها با نواحی بین چشم ها را اندازه می گیرد. با استفاده از ویژگی های انتخاب شده، یک درخت نا متعادل ساخته می شود که به آن کلاسیفایر Cascade می گویند. به شکل های ریر دقت کنید:


پارامتر در Cascade به طوری تنظیم می شود که در هر نود درخت، ما یک انشعاب not a face داریم و به این معنی است که، تصویر یک تصویر چهره نبوده و یا به عبارت دیگر نرخ false negative در حال به حداقل رسیدن می باشد. ایده ی این طرح در واقع شناسایی زودتر تصویر غیر چهره می باشد. به طور متوسط در هر زیر تصویر 10 تا ویژگی را مورد بررسی قرار می دهیم. انجام یک سری آزمایش viola-jones بر روی تصاویر:


منابع:
P. Viola and M. Jones, "Robust Real-time Face Detection," presented at Eighth IEEE International Conference on Computer Vision, vol. 2,pp. 747,January 2001. [
P. Viola, M. J. Jones, and D. Snow, "Detecting Pedestrians Using Patterns of Motion and Appearance," presented at Proceedings of the Ninth IEEE International Conference on Computer Vision(ICCV’03), 2003.