آنالیز تفکیک خطی LDA
آنالیز تفکیک خطی یکی از قدرتمند ترین الگوریتم های کاهش ابعاد مسئله می باشد. در بسیاری از موارد هدف طبقه بندی یا کلاس بندی نمودن نمونه ها توسط یک سیستم هوشمند است که در اصطلاح قدرت تشخیص را برای سیستم فراهم می آورد.
در بسیاری از موارد حجم اطلاعات و ویژگی ها به اندازه ای بالاست که طبقه بندی کننده ها را دچار چالش می نماید که حتی اگر طبقه بندی مقدور باشه دقت بالایی به دست نمی آید. از این رو با حفظ اطلاعات مهم نمونه ها برای طبقه بندی نیاز است تا حجم اطاعات کاهش یابد.
الگوریتم هایی نظیر آنالیز تجرای اصلی با رویکرد انتقال به فضایی که بیشترین تمایز بین داده ها وجود دارد حجم اطلاعات را کاهش می دهند اما در مقابل آنالیز تفکیک خطی ایده متفاوتی دارد.
ایده اصلی این الگوریتم توجه به کلاس نمونه هاست به این گونه که الگوریتم به دنبال انتقال به فضای کاهش یافته ای است که در آن نمونه های هر کلاس حداقل فاصله را داشته باشند و کلاس ها با سایر کلاس ها حداکثر فاصله را داشته باشند.
برای این منظور دو اسکاتر ماتریس تعریف می شود ماتریس اول برای نمونه های هر کلاس می باشد به این صورت که برای هر کلاس میانگین نمونه های کلاس محاسبه شده و در ادامه فاصله همه نمونه ها با میانگین کلاس محاسبه شده و در ماتریس قرار می گیرد. در ادامه فاصله میانگین هر کلاس با میانگین کل محاسبه شده و در ماتریس بین کلاسی قرار می گیرد. حال مقادیر ویژه و بردارهای ویژه به نحوی محاسبه می شوند که نمونه های هر کلاس حداقل فاصله و بین کلاس ها حداکثر فاصله باشد.حال مقادیر ویژه را به صورت نزولی مرتب می کنیم و تعدادی که درصد انرژی مناسب را برای ما فراهم می نماید انتخاب می کنیم. بردارهای ویژه نظیر این مقادیر ویژه را انتخاب نموده و برای ساخت ماتریس انتقال مورد استفاده قرار می دهیم . در انتها هر نمونه جدید با ضرب در ماتریس انتقال به بعد کاهش یافته منتقل می شود.
شایان ذکر است در بسیار از موارد این الگوریتم با الگوریتم PCA و پشت سرهم مورد استفاده قرار می گیرند.
آنالیز اجزای اصلی PCA
آنالیز اجزای اصلی یکی از پایه ای ترین الگوریتم ها در زمینه کاهش ابعاد مسئله می باشد. در بسیاری از مسائل به دلیل حجم بالای اطلاعات یا ویژگی ها نیاز است تا حجم اطلاعات را کاهش دهیم و این کاهش می بایست به نحوی صورت پذیرد که اطلاعات مهم را از بین نبرده و پردازش های بعدی و یا تصمیم گیری را دچار مشکل نکند. حوزه پردازش تصاویر دیجیتال یکی از حوزه هایی است که کاهش ابعاد در آن بسیار پر کاربرد است. ایده اصلی PCA بر این اصل استوار است که در فضای کاهش یافته نمونه باید حداکثر تمایز را با یکدیگر داشته باشند. برای رسیدن به این مقصود راهکار به این صورت می باشد که اگر اطلاعات یا ویژگی ها رابه ازای هر نمونه یک بردار یا آرایه در نظر بگیریم ، در ابتدا بینم بردارهای همه نمونه میانگین گیری انجام می شود و یک بردار میانگین به دست می آید در ادامه فاصله تک تک نمونه ها را با بردار میانگین محاسبه می نماییم که حاصل یک ماتریس بدست می آید حال ماتریس به دست آمده را در ترانهاده آن ضرب می کنیم که باعث می شودماتریس کواریانس حاصل شود. حال مقادیر ویژه و بردار های ویژه این ماتریس را محاسبه می نمایم . پس از محاسبه مقادیر ویژه آنها رابه ترتیب نزولی مرتب می نماییم . هر مقدار ویژه بردار ویژه ای نظیر خورد دارد و هر چه مقدار یک مقدار ویژه بزرگتر باشد به این معناست که در آن بعد تمایز بیشتری برای داده ها وجود دارد.
نکته حائز اهمیت انتخاب تعداد مقادیر ویژه است معمولا برای این منظور پارامتر به اسم درصد انرژی تعریف می شود که حاصل تقسیم مقدار همه مقادیر ویژه انتخاب شده به کل مقادیر ویژه می باشد .پس از انتخاب مقادیر ویژه بزرگتر ، بردارهای ویژه نظیر را انتخاب کرده در ماتریس کواریانس ضرب می نماییم و به این گونه ماتریس پروجکشن یا انتقال به دست می آید.
از این پس برای هر نمونه جدید کافیست تابردار میانگین را از بردار ویژگی ها ی جدید کم نموده و در این ماتریس انتقال ضرب نماییم تا بردار ویژگی به بعد کاهش یافته انتقال یابد.
در برخی مسائل به دلیل زیاد بودن ویژگی ها و عدم توانایی محاسبه مقادیر و بردارهای ویژه ، از معکوس PCA یا IPCA استفاده می شود که به جای ضرب ماتریس کواریانس در ترانهاده اش ، ترانهاده ماتریس را در خودش ضرب می نمایند.
Y. V.Lata, CH.K.B.Tungathurthi, H.R.M.Rao, A. Govardhan and L. P. Reddy. Facial
Recognition Using Eigenfaces By PCA. International Journal of Recent Trends in Engineering, Vol.
1, No. 1, May 2009.
حساسیت و تشخیص
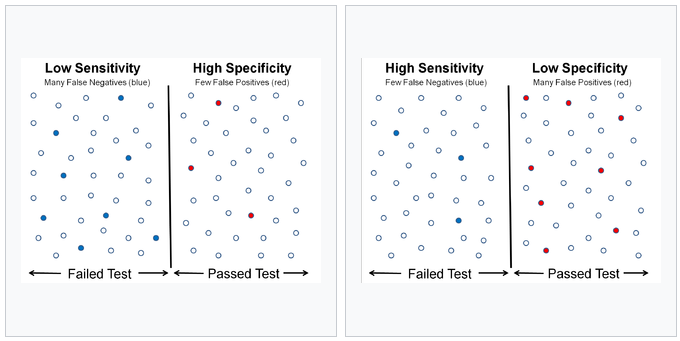
در آمار دو شاخص برای ارزیابی نتیجه ی یک آزمایش دسته بندی دو دویی(دو حالته) هستند. زمانی که بتوان داده ها را به دو گروه مثبت و منفی تقسیم کرد، دقت نتایج یک آزمایش که اطلاعات را به این دو دسته تقسیم می کند با استفاده از شاخص های حساسیت و ویژگی قابل اندازه گیری و توصیف است. (true positiverate) به معنی نسبتی از موارد مثبت است که آزمایش آن ها را به درستی به عنوان مثبت علامت گذاری می کند. تشخیص (true negative rate) به معنی نسبتی از موارد منفی است که آزمایش آن ها را به درستی به عنوان منفی علامت گذاری می کند.
مثبت صحیح(True Positive): شخص بیمار، به درستی بیمار تشخیص داده شود.
مثیت کاذب(False Positive): شخص سالم، به اشتباه بیمار تشخیص داده شود.
منفی صحیح(True Negative): شخص سالم، به درستی سالم تشخیص داده شود.
منفی کاذب(False Negative): شخص بیمار، به اشتباه سالم تشخیص داده شود.
به بیان ریاضی، حساسیت حاصل تقسیم موارد مثبت واقعی به حاصل جمع موارد مثبت واقعی و موارد منفی کاذب است.
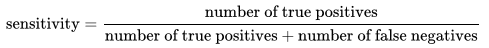
به همین شکل، تشخیص حاصل تقسیم موارد منفی واقعی به حاصل جمع موارد منفی واقعی و مثبت کاذب است.
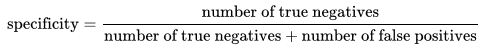
حساسیت و تشخیص یک آزمایش تنها به ماهیت آزمایش و نمونه ای که آزمایش در آن استفاده می شود بستگی دارد. با این حال، فقط با استفاده از حساسیت و ویژگی نمی توان نتیجه یک آزمایش را تعبیر کرد. به عنوان مثال، اگر نتیجه ی آزمایش خون یک بیمار حاکی از ابتلای وی به یک بیمار باشد و این آزمایش حساسیت 90 درصد و ویژگی 96 درصد داشته باشد، پزشک نمی تواند فقط با داشتن این دو مشخص کند که چند درصد احتمال دارد که بیمار واقعا به آن بیماری مبتلا باشد. برای چنین منظوری، باید ارزش اخباری مثبت (یا ارزش اخباری منفی در صورت منفی بودن نتیجه آزمایش) را در نظر گرفت. ارزش اخباری یک آزمایش، علاوه بر ماهیت آزمایش و نمونه، به شیوع پدیده ی مورد آزمایش در جامعه ی آماری هم بستگی دارد.
https://fa.m.wikipedia.org/wiki/%D8%AD%D8%B3%D8%A7%D8%B3%DB%8C%D8%AA_%D9%88_%D9%88%DB%8C%DA%98%DA%AF%DB%8C
اعتبارسنجی ضربدری Cross Validation
اعتبار سنجی ضربدری ، که گاهی تخمین گردشی نیز نامیده می شود، یک روش ارزیابی است که نتایج یک تحلیل آماری بر روی یک مجموعه ی داده تا چه اندازه قابل تعمیم و مستقل از داده های آموزشی است. این تکنیک به طور ویژه در کاربرد های پیش بینی مورد استفاده قرار می گیرد تا مشخص شود مدل مورد نظر تا چه اندازه در عمل مفید خواهد بود. به طور کلی یک دور از اعتبارسنجی ضربدری شامل افراز داده ها به دو زیر مجموعه مکمل، انجام تحلیل بر روی یکی از آن زیر مجموعه ها (داده های آموزشی) و اعتبار سنجی تحلیل با استفاده از داده های مجموعه ی دیگر است (داده های اعتبار سنجی یا تست).اعتبار ستجی ضربدری یا متقابل ( cross validation ) انواع مختلفی دارد که در ادامه سه نوع از معروفترین و پر کاربردترین انواع آن معرفی می شود:
k-Fold
در این نوع اعتبار سنجی داده ها به k زیر مجموعه افراز می شوند. از این k زیر مجموعه، هر بار یکی برای اعتبارسنجی و k-1 دیگر برای آموزش بکار می روند. این روال k بار تکرار می شود و همه داده ها دقیقا یکبار برای آموزش و یک بار برای اعتبار سنجی بکار می روند. در نهایت میانگین نتیجه این k بار اعتبار سنجی به عنوان یک تخمین نهایی برگزیده می شود. البته می توان از روش های دیگر برای ترکیب نتایج استفاده کرد. در این روش که از دسته روش های فراگیر است اطمینان حاصل می شود همه نمونه ها حداقل یکبار در مجموعه تست قرار گرفته و جز مجموعه آموزش نبوده اند.
در روش k-Fold طبقه ای سعی می شود نسبت داده های هر کلاس در هر زیر مجموعه و در مجموعه اصلی یکسان باشد.
نمونه گیری چندباره تصادفی random variation
در این نوع اعتبار سنجی مجموعه داده ها به دو زیر مجموعه داده ها به دو زیر مجموعه ی آموزش و تست تقسیم می شود. سپس مدل مورد نظر با استفاده از داده های آموزشی آموزش داده می شود و نتیجه با استفاده از داده های تست اعتبار سنجی می شود. این روال چندین بار تکرار می شود و میانگین نتایج به عنوان تخمین نهایی در نظر گرفته می شود. مزیت این روش آن است که نسبت داده های آموزش و تست به تعدادتکرارها وابسته نیست بر خلاف روش k-fold که نعداد تکرارها الزاما ضریبی از k می باشد. عیب این روش آن است که بعضی داده ها ممکن است هرگز برای اعتبار سنجی استفاده نشوند و برخی دیگر ممکن است چند بار مورد استفاده قرار گیرند. به عبارت دیگر زیر مجموعه ها می توانند با هم هم پوشانی داشته باشند. این روش در واقع از آزمایشات مونته کارلو می باشد.
یکی-بیرون leave one out
همان طور که از اسم این روش پیداست در هر مرحله یکی از داده ها برای اعتبار سنجی بیرون گذاشته می شود و بقیه داده ها برای آموزش استفاده می شوند. این روش در واقع همان روش k-Fold است که در آن k برابر تعداد داده ها در نظر گرفته شده است. این روش از نظر محاسباتی بسیار پر هزینه است زیرا فرآیند آموزش و اعتبارسنجی به تعداد بسیار زیادی تکرار می شود.
https://www.porseshkadeh.com/Question/42019/cross-validation-%DA%86%DB%8C%D8%B3%D8%AA
طبقه بندی مبتنی بر نمایش پراکنده (Sparse Representation-based Classification)
SRC بر مبنای حس کردن فشرده (CS) توسعه یافته است. اصل روش SRC بر مبنای این فرض است که کل مجموعه نمونه های آموزشی برای تشکیل یک دیکشنری استفاده می شوند و بنابراین، مسئله ی طبقه بندی به صورت مسئله ی جست و جوی متمایز کننده ی نمایش پراکنده ی نمونه تست به صورت ترکیب خطی نمونه های آموزشی با حل مسئله بهینه سازی معیار L1 در نظر گرفته می شود. در حالت رسمی، برای نمونه های آموزشی یک کلاس، این فرض می تواند به صورت زیر فرموله شود:

که در آن  نشان دهنده ی نمونه تست K امین کلاس است،
نشان دهنده ی نمونه تست K امین کلاس است، نشان دهنده ی i امین نمونه ی آموزشی K امین کلاس است،
نشان دهنده ی i امین نمونه ی آموزشی K امین کلاس است، نشان دهنده ی وزن متناظر وزن است و
نشان دهنده ی وزن متناظر وزن است و  نشان دهنده ی خطای تقریب است.
نشان دهنده ی خطای تقریب است.
برای نمونه های آموزشی از تمام C کلاس شی، معادله بالا می تواند به صورت زیر بازنویسی شود:

در فرم ماتریس، برابر است با:
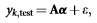
با شرط:
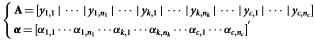
برای دستیابی به بردار وزن  ،مسئله ی کمینه سازی معیار L1 زیر باید حل شود:
،مسئله ی کمینه سازی معیار L1 زیر باید حل شود:

که یک مسئله ی بهینه سازی محدب است و می تواند با روش برنامه نویسی درجه دوم حل شود. زمانی که راه حل پراکنده ی ارائه می شود، روند طبقه بندی SRC به صورت زیر خلاصه می شود:
ارائه می شود، روند طبقه بندی SRC به صورت زیر خلاصه می شود:
گام 1: حل مسئله ی معادله کمینه سازی معیار L1.
گام 2: برای هر کلاس i، محاسبه ی باقیمانده های بین نمونه ی بازسازی شده ی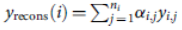 و تست مورد نظر
و تست مورد نظر
گام 3: برچسب کلاس نمونه تست مشخص با استفاده از قاعده زیر تعیین می شود: شناسایی 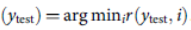 .
.
در کارهای قبلی، کارایی SRC هنگام طبقه بندی تصاویر حالت چهره واضح یا مات مورد بررسی قرار گرفته است و پی برده شده است که SRC، کارایی بهتر و قدرت بالاتری در مقایسه با نزدیک ترین همسایه (NN)، نزدیک ترین زیر فضا(NS) و SVM داشته است. گروه تحقیقاتی محمدی، یک دیکشنری مبتنی بر PCA با ساخت نمایش پراکنده و طبقه بندی حالت های چهره جهانی ارائه کرده است. در جزییات، تصاویر چهره های گویای هر فرد ابتدا از تصویر چهره ی خنثی همان فرد کسر شدند. سپس، روش PCA برای این تصاویر متفاوت جهت مدل سازی واریانس های درون هر کلاس حالت چهره به کار گرفته شد. مؤلفه های اصلی یاد گرفته شده به عنوان اجزای سازنده ی دیکشنری به کار گرفته شدند. در نهایت، برای طبقه بندی، تصویر تست مورد نظر به طور پراکنده به صورت ترکیب خطی مؤلفه های اصلی شش حالت چهره پایه نمایش داده شد. گروه تحقیقاتی اویانگ اخیرا FER دقیق و قوی را با ترکیب طبقه بندی کننده های مبتنی بر نمایش پراکنده چند گانه توسعه داده است، یعنی ترکیب HOGCSRC و LBPCSRC.