K نزدیک ترین همسایه (K-nearest neighbour)
الگوریتم نزدیکترین همسایگی برای طبقه بندی یا classification رگرسیون regression کاربرد دارد . این راهکار در فاز آموزش شامل تعداد نقاط آموزشی با کلاس یا برچسب مشخص می باشد و پس از آن برای نمونه های جدید در فاز تست ، کلاس خروجی بر اساس آرای k تا از نزدیکترین همسایه هایش مشخص می شود که اگر k=1 باشد کلاس نمونه بر اساس کلاس نزدیکترین همسایه تعیین می شود.
در متلب برای ایجاد یک مدل طبقه بندی knn تابع مناسب تعریف شده و می توان از آن استفاده نمود به طور مثال قطعه کد زیر :
load fisheriris
X = meas;
Y = species;
Mdl = fitcknn(X,Y,'NumNeighbors',5)
در این مثال از دیتاست تعریف شده fisheriris استفاده شده است که شامل داده های گل ها در متغیر X,meas ورودی ها و Y,species برچسب ها یا انواع گل ها می باشد برای ساخت مدل طبقه بندی از تابع fitcknn استفاده شده است که تعداد همسایه ها نیز 5 در نظر گرفته شده است .
قطعه کد زیر نحوه استفاده و خروجی را برای مدل ساخته شده با استفاده از تابع predict نشان می دهد.
predict(Mdl,X(2,:))
ans =
cell
'setosa'
چنانچه ملاحظه می شود مدل به درستی کلاس نمونه دوم را که ‘setosa’ می باشد را تشخیص داده است.
طبقه بندی مبتنی بر نمایش پراکنده (Sparse Representation-based Classification)
SRC بر مبنای حس کردن فشرده (CS) توسعه یافته است. اصل روش SRC بر مبنای این فرض است که کل مجموعه نمونه های آموزشی برای تشکیل یک دیکشنری استفاده می شوند و بنابراین، مسئله ی طبقه بندی به صورت مسئله ی جست و جوی متمایز کننده ی نمایش پراکنده ی نمونه تست به صورت ترکیب خطی نمونه های آموزشی با حل مسئله بهینه سازی معیار L1 در نظر گرفته می شود. در حالت رسمی، برای نمونه های آموزشی یک کلاس، این فرض می تواند به صورت زیر فرموله شود:

که در آن  نشان دهنده ی نمونه تست K امین کلاس است،
نشان دهنده ی نمونه تست K امین کلاس است، نشان دهنده ی i امین نمونه ی آموزشی K امین کلاس است،
نشان دهنده ی i امین نمونه ی آموزشی K امین کلاس است، نشان دهنده ی وزن متناظر وزن است و
نشان دهنده ی وزن متناظر وزن است و  نشان دهنده ی خطای تقریب است.
نشان دهنده ی خطای تقریب است.
برای نمونه های آموزشی از تمام C کلاس شی، معادله بالا می تواند به صورت زیر بازنویسی شود:

در فرم ماتریس، برابر است با:
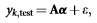
با شرط:
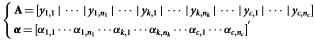
برای دستیابی به بردار وزن  ،مسئله ی کمینه سازی معیار L1 زیر باید حل شود:
،مسئله ی کمینه سازی معیار L1 زیر باید حل شود:

که یک مسئله ی بهینه سازی محدب است و می تواند با روش برنامه نویسی درجه دوم حل شود. زمانی که راه حل پراکنده ی ارائه می شود، روند طبقه بندی SRC به صورت زیر خلاصه می شود:
ارائه می شود، روند طبقه بندی SRC به صورت زیر خلاصه می شود:
گام 1: حل مسئله ی معادله کمینه سازی معیار L1.
گام 2: برای هر کلاس i، محاسبه ی باقیمانده های بین نمونه ی بازسازی شده ی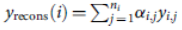 و تست مورد نظر
و تست مورد نظر
گام 3: برچسب کلاس نمونه تست مشخص با استفاده از قاعده زیر تعیین می شود: شناسایی 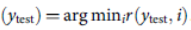 .
.
در کارهای قبلی، کارایی SRC هنگام طبقه بندی تصاویر حالت چهره واضح یا مات مورد بررسی قرار گرفته است و پی برده شده است که SRC، کارایی بهتر و قدرت بالاتری در مقایسه با نزدیک ترین همسایه (NN)، نزدیک ترین زیر فضا(NS) و SVM داشته است. گروه تحقیقاتی محمدی، یک دیکشنری مبتنی بر PCA با ساخت نمایش پراکنده و طبقه بندی حالت های چهره جهانی ارائه کرده است. در جزییات، تصاویر چهره های گویای هر فرد ابتدا از تصویر چهره ی خنثی همان فرد کسر شدند. سپس، روش PCA برای این تصاویر متفاوت جهت مدل سازی واریانس های درون هر کلاس حالت چهره به کار گرفته شد. مؤلفه های اصلی یاد گرفته شده به عنوان اجزای سازنده ی دیکشنری به کار گرفته شدند. در نهایت، برای طبقه بندی، تصویر تست مورد نظر به طور پراکنده به صورت ترکیب خطی مؤلفه های اصلی شش حالت چهره پایه نمایش داده شد. گروه تحقیقاتی اویانگ اخیرا FER دقیق و قوی را با ترکیب طبقه بندی کننده های مبتنی بر نمایش پراکنده چند گانه توسعه داده است، یعنی ترکیب HOGCSRC و LBPCSRC.
ماشین بردار پشتیبان(Support vector machine)
SVM ها (Support vector machine) بر مبنای اصل کمینه سازی ریسک ساختاری توسعه می یابند که نشان داده شده است که برتر از اصل کمینه سازی ریسک تجربی سابق استفاده شده توسط شبکه های عصبی قراردادی می باشند. اصل SVM، تبدیل بردارهای ورودی به فضایی با ابعاد بیشتر توسط تبدیل غیر خطی و سپس ابر صفحه ی بهینه است که داده هایی را که قابل یافتن هستند را تفکیک می کند. با در نظر گرفتن مجموعه آموزشی 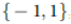
 ، برای جست و جوی ابر صفحه ی بهینه، تبدیل غیر خطی
، برای جست و جوی ابر صفحه ی بهینه، تبدیل غیر خطی 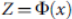 برای قابل تقسیم ساختن خطی داده های آموزشی استفاده می شود. وزن w و مبدأ b طبق ضوابط زیر در نظر گرفته می شوند:
برای قابل تقسیم ساختن خطی داده های آموزشی استفاده می شود. وزن w و مبدأ b طبق ضوابط زیر در نظر گرفته می شوند:

روند بالا با استفاده از مسئله بهینه سازی زیر خاتمه می یابد:
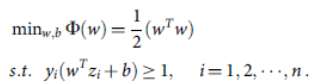
با استفاده از روش لاگرانژ، تابع تصمیم می تواند به صورت زیر نوشته شود:

طبق ایده ی هسته ای، تابع تقارن غیر منفی K(u ,v) به طور منحصر به فرد، فضای هیلبرت H را نشان می دهد:

که در آن K، تابع هسته در فضای H است که نشان دهنده ضرب داخلی در فضای هیلبرت H است:

بنابراین، تابع تصمیم می تواند به صورت زیر بازنویسی شود:

چهار تابع هسته نوعی برای مدل SVM استفاده شده وجود دارد که شامل هسته خطی، هسته چند جمله ای، هسته RBF و هسته حلقوی است که به صورت زیر بیان می شود:
تابع هسته خطی برابر است با:

تابع هسته ی چند جمله ای برابر است با:

تابع هسته ی RBF برابر است با:
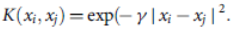
تابع هسته ی حلقوی برابر است با:

یورتکان و دمیرل از طبقه بندی کننده ی SVM برای توسعه ی سیستم انتخاب ویژگی برای FER بهبود یافته با استفاده از موقعیت های نقطه ی ویژگی چهره ی هندسی سه بعدی استفاده کردند. گیمیر و لی روش FER مبتنی بر ویژگی هندسی را در دنباله های تصویر چهره ارائه کردند و صحت %97.35 را با استفاده از دسته بندی کننده SVM روی پایگاه داده ی Cohn-Kanade گزارش کردند.
K نزدیک ترین همسایه (K-nearest neighbour)
KNN نوعی الگوریتم دسته بندی یادگیری مبتنی بر نمونه است. اصل روش KNN این است که در فضای ویژگی، یک نمونه دارای K نزدیک ترین نمونه است و برچسبش به رایج ترین کلاس در میان KNN هایش با استفاده از رأی اکثریت همسایه هایش تخصیص می یابد. بدون دانش قبلی، الگوریتم دسته بندی KNN به طور متناوب از فاصله اقلیدسی به عنوان معیار فاصله استفاده می کند. با در نظر گرفتن دو بردار x = ( x1 , x2 , ... ,xm ) و y = ( y1 , y2 , ... , ym ) ، فاصله اقلیدسی آن ها به صورت زیر نمایش داده می شود:
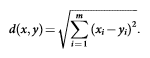
گروه تحقیقاتی سیبی از ویژگی های هندسی برای دستیابی به بهترین صحت دسته بندی 93% روی پایگاه داده ی Cohn-Kanade با روش KNN استفاده کرده است. گروه تحقیقاتی گو، روش FER را با استفاده از رمز گذاری شعاعی ویژگی های محلی گابور و سنتز دسته بندی کننده ی مبتنی بر روش KNN با K=1 اراِئه کرده است.
دسته بندی حالت چهره (Facial expression classification)
هدف دسته بندی حالت چهره ، طراحی یک مکانیزم دسته بندی مناسب برای شناسایی حالت چهره است. روش های دسته بندی نمونه برای FER شامل مدل مارکوف نهفته (Hidden Markov Model)، شبکه عصبی مصنوعی (Artificial Neural Network)، شبکه بیز (Bayesian Network)، نk نزدیک ترین همسایه (K-nearest neighbour)، ماشین های بردار پشتیبان (Support Vector Machines)، دسته بندی مبتنی بر نمایش پراکنده(Sparse Representation-based Classification)، و مواردی از این قبیل می باشند.